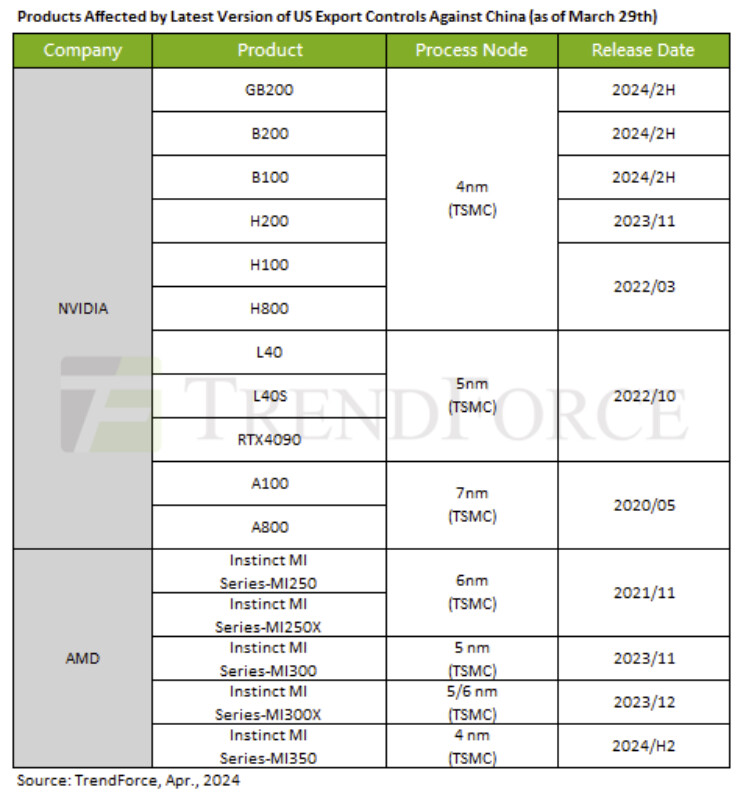
Finally, competition emerges that threatens to put Nvidia on the ropes.
Oracle and AMD to Launch First AI Supercluster with 50,000 AMD Instinct MI450 GPUs in 2026.

October 14, 2025 – Oracle and AMD have announced a groundbreaking collaboration to deploy the first publicly available AI supercluster powered by 50,000 AMD Instinct MI450 Series GPUs, starting in Q3 2026. This initiative, revealed at Oracle AI World in Las Vegas and Santa Clara, marks a significant milestone in their decade-long partnership to advance AI infrastructure through Oracle Cloud Infrastructure (OCI).
Unprecedented AI Performance
The supercluster, expanding in 2027, will leverage AMD’s “Helios” rack design, featuring:
AMD Instinct MI450 Series GPUs: Offering up to 432 GB of HBM4 and 20 TB/s memory bandwidth for faster, larger-scale AI training and inference.
Next-Gen AMD EPYC “Venice” CPUs: Providing confidential computing and robust security for sensitive AI workloads.
AMD Pensando “Vulcano” Networking: Enabling ultra-fast, lossless connectivity with up to three 800 Gbps AI-NICs per GPU.
UALink and UALoE Fabric: Supporting scalable, low-latency GPU interconnectivity for multi-trillion-parameter models.
This architecture ensures maximum performance, energy efficiency, and scalability for demanding AI and HPC workloads.
Why It Matters
With AI models rapidly outgrowing current infrastructure, Oracle’s supercluster addresses the need for flexible, high-performance solutions. Key benefits include:
Breakthrough Compute: Handles 50% larger models in-memory, reducing model partitioning.
Scalable Design: Dense, liquid-cooled 72-GPU racks optimize cost and efficiency.
Open-Source Support: AMD ROCm™ software stack simplifies migration and supports popular AI frameworks.
Advanced Security: DPU-accelerated networking and EPYC CPUs enhance data protection.
Building on Proven Success
This announcement builds on OCI’s prior integration of AMD Instinct MI300X and MI355X GPUs, with the latter now generally available in OCI’s zettascale Supercluster, scaling up to 131,072 GPUs. These solutions offer unmatched price-performance and flexibility for generative AI and large language models.
Industry Impact
Mahesh Thiagarajan, EVP at OCI, emphasized, “Our customers are pushing AI boundaries, and this collaboration with AMD delivers the scalable, secure infrastructure they need.” Forrest Norrod, AMD’s EVP, added, “Together, we’re accelerating AI innovation with open, optimized systems.”
For more details, visit Oracle’s AI solutions or AMD’s Instinct GPUs.
Keywords: Oracle AI Supercluster, AMD Instinct MI450, AI infrastructure, cloud computing, generative AI, high-performance computing